개인 공부/너 F야?(가칭)
데이터셋을 전처리 해보자 (1)
nanocat
2024. 7. 8. 17:08
데이터셋은 AI-Hub의 '감성 대화 말뭉치'를 가져와서 사용하였습니다.
https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&dataSetSn=86
AI-Hub
샘플 데이터 ? ※샘플데이터는 데이터의 이해를 돕기 위해 별도로 가공하여 제공하는 정보로써 원본 데이터와 차이가 있을 수 있으며, 데이터에 따라서 민감한 정보는 일부 마스킹(*) 처리가 되
aihub.or.kr
colab에서 코드를 작성했습니다.
from google.colab import drive
drive.mount('/content/drive') # 구글 드라이브를 마운트 합니다.path = "/content/drive/MyDrive/Colab Notebooks/data/Emotion_Chat/"
# 데이터가 있는 경로입니다.raw_train = pd.read_excel(path + "train.xlsx")
raw_test = pd.read_excel(path + "test.xlsx")# 데이터프레임 섞기
shuffled_train = raw_train.sample(frac=1).reset_index(drop=True)
shuffled_test = raw_test.sample(frac=1).reset_index(drop=True)데이터프레임을 미리 섞는 이유는 대화 내용이 이어지기 때문입니다. 이따가 분리할 것이기 때문에 미리 섞습니다.
shuffled_train.head()
원천 데이터는 이렇습니다.
# 빈 리스트를 만들어 데이터를 저장
rows = []
# 각 행에 대해 사람문장과 시스템문장을 분리
for idx, row in shuffled_train.iterrows():
# 사람문장1에 대한 시스템문장1
if pd.notna(row['사람문장1']) and pd.notna(row['시스템문장1']):
rows.append({
'연령': row['연령'],
'성별': row['성별'],
'상황키워드': row['상황키워드'],
'신체질환': row['신체질환'],
'감정_대분류': row['감정_대분류'],
'감정_소분류': row['감정_소분류'],
'사람문장': row['사람문장1'],
'시스템문장': row['시스템문장1']
})
# 사람문장2에 대한 시스템문장2
if pd.notna(row['사람문장2']) and pd.notna(row['시스템문장2']):
rows.append({
'연령': row['연령'],
'성별': row['성별'],
'상황키워드': row['상황키워드'],
'신체질환': row['신체질환'],
'감정_대분류': row['감정_대분류'],
'감정_소분류': row['감정_소분류'],
'사람문장': row['사람문장2'],
'시스템문장': row['시스템문장2']
})
# 사람문장3에 대한 시스템문장3 (NaN이 아닌 경우에만 추가)
if pd.notna(row['사람문장3']) and pd.notna(row['시스템문장3']):
rows.append({
'연령': row['연령'],
'성별': row['성별'],
'상황키워드': row['상황키워드'],
'신체질환': row['신체질환'],
'감정_대분류': row['감정_대분류'],
'감정_소분류': row['감정_소분류'],
'사람문장': row['사람문장3'],
'시스템문장': row['시스템문장3']
})
# 새로운 데이터 프레임 생성
train = pd.DataFrame(rows)# 빈 리스트를 만들어 데이터를 저장
rows = []
# 각 행에 대해 사람문장과 시스템문장을 분리
for idx, row in shuffled_test.iterrows():
# 사람문장1에 대한 시스템문장1
if pd.notna(row['사람문장1']) and pd.notna(row['시스템문장1']):
rows.append({
'연령': row['연령'],
'성별': row['성별'],
'상황키워드': row['상황키워드'],
'신체질환': row['신체질환'],
'감정_대분류': row['감정_대분류'],
'감정_소분류': row['감정_소분류'],
'사람문장': row['사람문장1'],
'시스템문장': row['시스템문장1']
})
# 사람문장2에 대한 시스템문장2
if pd.notna(row['사람문장2']) and pd.notna(row['시스템문장2']):
rows.append({
'연령': row['연령'],
'성별': row['성별'],
'상황키워드': row['상황키워드'],
'신체질환': row['신체질환'],
'감정_대분류': row['감정_대분류'],
'감정_소분류': row['감정_소분류'],
'사람문장': row['사람문장2'],
'시스템문장': row['시스템문장2']
})
# 사람문장3에 대한 시스템문장3 (NaN이 아닌 경우에만 추가)
if pd.notna(row['사람문장3']) and pd.notna(row['시스템문장3']):
rows.append({
'연령': row['연령'],
'성별': row['성별'],
'상황키워드': row['상황키워드'],
'신체질환': row['신체질환'],
'감정_대분류': row['감정_대분류'],
'감정_소분류': row['감정_소분류'],
'사람문장': row['사람문장3'],
'시스템문장': row['시스템문장3']
})
# 새로운 데이터 프레임 생성
test = pd.DataFrame(rows)사람문장1, 2, 3과 시스템문장1, 2, 3을 분리했습니다.
분리하는 코드는 ChatGPT의 도움을 받았습니다.
train.head()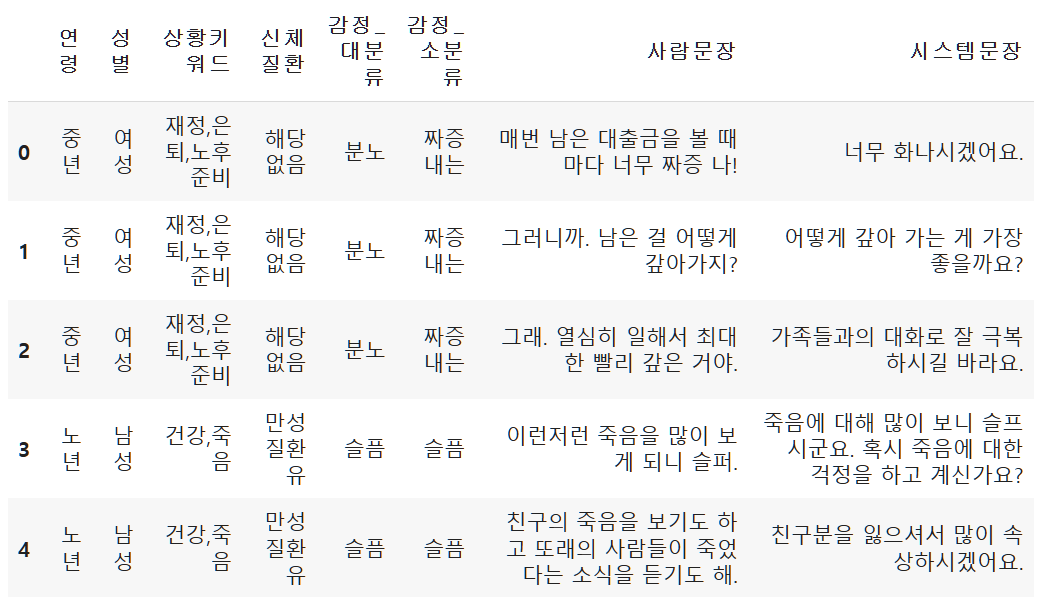
이렇게 데이터가 가공되었습니다.